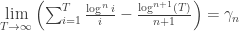From @infseriesbot, prove the identity: 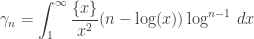
We have 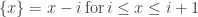
so

and since

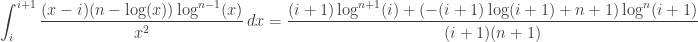
allora:
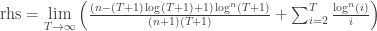
and since 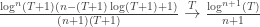
From the series representation of the Stieltjes Gamma function, 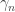
From @infseriesbot, prove the identity:
We have
so
and since
allora:
and since
From the series representation of the Stieltjes Gamma function,
A maximum entropy alternative to Bayesian methods for the estimation of independent Bernouilli sums.
Let 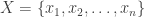

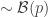
We propose that the probablity that provides the best statistical overview, 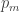
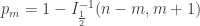
where 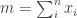

EMPIRICAL: The sample frequency corresponding to the “empirical” distribution 
BAYESIAN: The standard Bayesian approach is to start with, for prior, the parametrized Beta Distribution 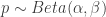

with mean 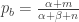
Let 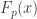
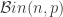
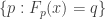
To get the maximum entropy probability, we need to maximize 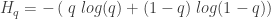

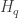
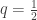
Now we must find p by inverting the CDF. Allora for the general case,

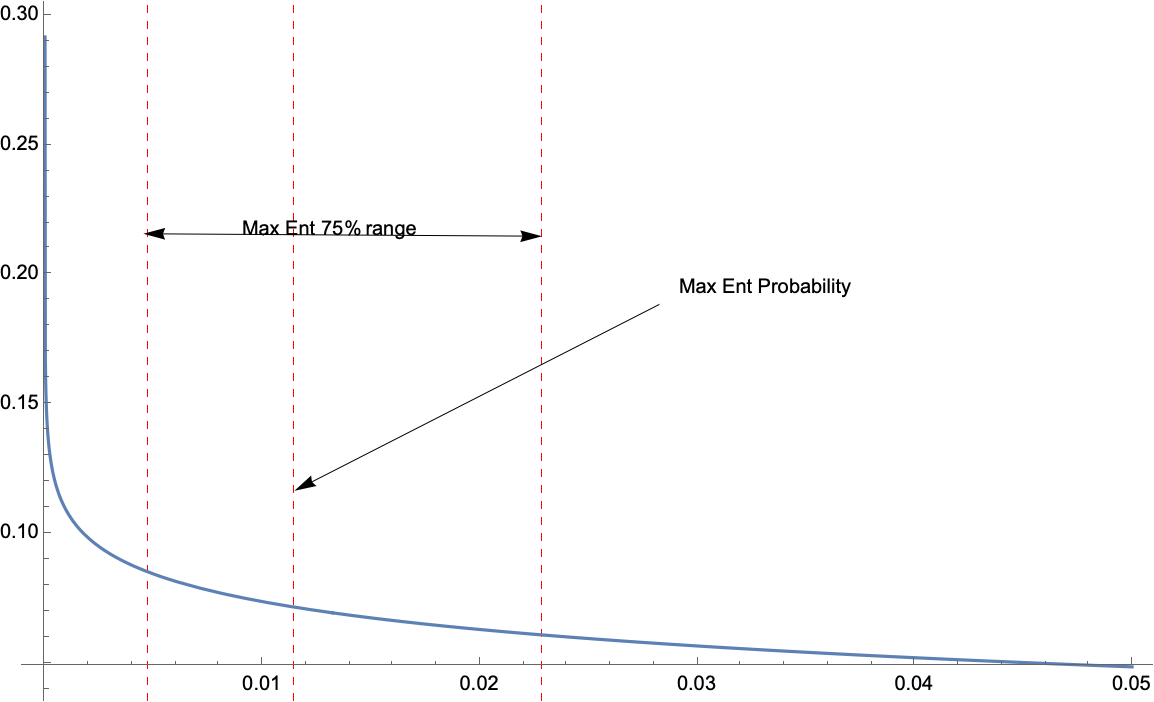
And note that as in the graph below (thanks to comments below by überstatistician Andrew Gelman), we can have a “confidence band” (sort of) with
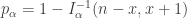
in the graph below the band is for values of: 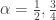
Case (Real World): A thoraxic surgeon who does mostly cardiac and lung transplants (in addition to emergency bypass and aortic ruptures) operates in a business with around 5% perioperative mortality. So far in his new position in the U.S. he has done 60 surgeries with 0 mortality.
What can we reasonable say, statistically, about his error probability?
Note that there may be selection bias in his unit, which is no problem for our analysis: the probability we get is conditional on being selected to be operated on by that specific doctor in that specific unit.
Assuming independence, we are concerned with 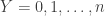
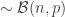

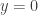
Here applying (1) with 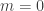
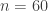
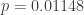
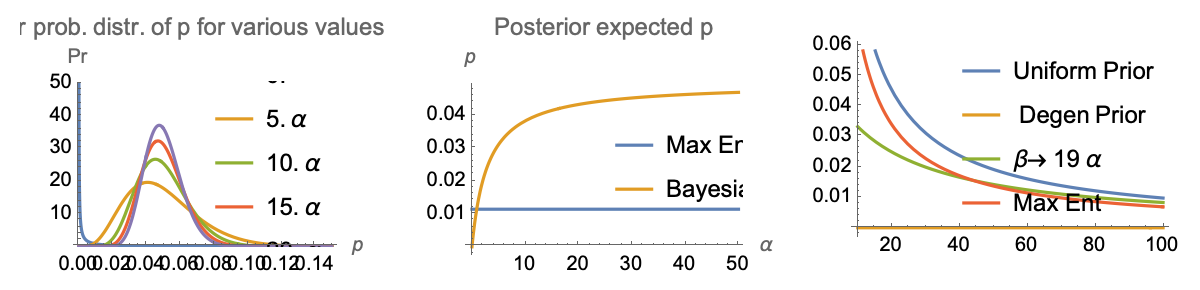
Why is this preferable to a Bayesian approach when, say, n is moderately large?
A Bayesian would start with a prior expectation of, say .05, and update based on information. But it is highly arbitrary. Since the mean is 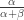
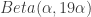
When I worked on this problem, and posted the initial derivations, I wasn’t aware of Jaynes’ “Brandeis Problem”. It is not the same as mine as it ignores n and it led to a dead-end because the multinomial is unwieldy. But his approach would have easily let to more work if we had computational abilities then (maximization, as one can see below, can be seamless).

Thanks to Saar Wilf for useful discussions.